
Why General-Purpose Robots Cannot Be Pretrained
From Pretraining to Experience-Scaling Embodied AI

This article is based on my UpperBound 2026 talk in Edmonton, Canada on May 21.
I used chatgpt to transcribe my talk to texts, and then revised the paragraphs. I have proof-read all the texts below.
I. The Field’s Prevailing Bet
Over the last few years, embodied foundation models have made real progress. Systems such as Gato, RT-1, PaLM-E, RT-2, OpenVLA, (\pi_0), (\pi_{0.5}), Gemini Robotics, and GR00T make it reasonable for the field to believe that robotics may follow a trajectory similar to NLP: large-scale pretraining, post-training (SFT/RL), reasoning, and then increasingly general capability.
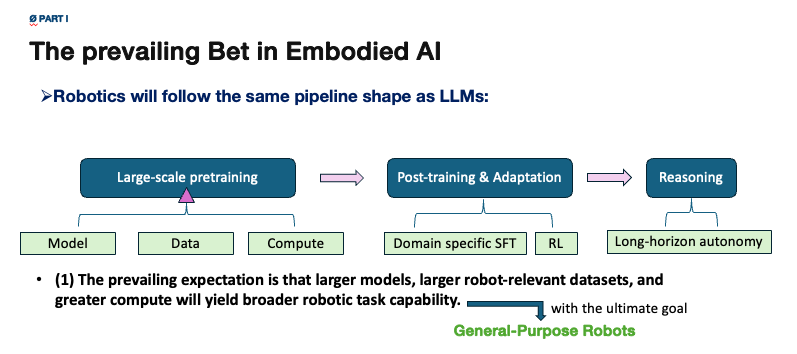
That is the strongest and fairest version of the field’s prevailing bet.
Larger models, larger robot-relevant datasets, and greater compute may yield broader robotic task capability. With a sufficiently strong pretrained backbone, domain-specific post-training -- supervised fine-tuning, reinforcement learning, or both -- may become easier and more data-efficient.
If the backbone becomes strong enough, embodied reasoning and long-horizon autonomy may also improve.
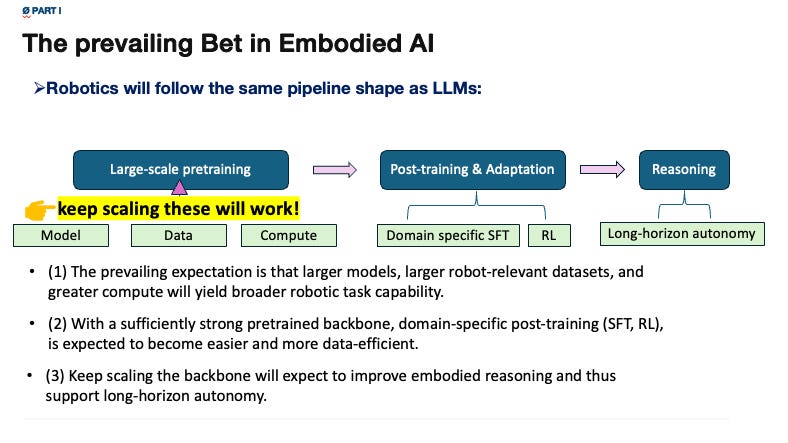
In the most optimistic version, robotics eventually reaches a GPT-like moment: a scaling threshold after which qualitatively stronger out-of-distribution task performance begins to appear.
I do not want to dismiss this view too quickly. It is an understandable view of course. Large Language Models changed how many researchers think about intelligence, representation learning, and the scaling law. It is natural to ask whether the same broad recipe can work in robotics.
But the key word is broad. Robotics may inherit the broad pipeline shape of NLP without inheriting the same sufficiency condition. What does it mean? I will explain more gradually.
My question is not whether pretraining helps. It clearly does. My question is whether static pretraining is enough for open-world embodied intelligence. In my opinion, even RL post-training is not the correct rescue.
To make that question precise, we need to be careful about what we mean by a scaling law.
A weak version of the claim says that average benchmark scores improve as we increase data, model size, and compute.
That kind of improvement is important, but it is not the main issue here. The stronger claim is that scaling reliably produces qualitatively stronger out-of-distribution performance.
After the scale threshold, we see scaling helps! Before the scale threshold, the test results are just random noise.
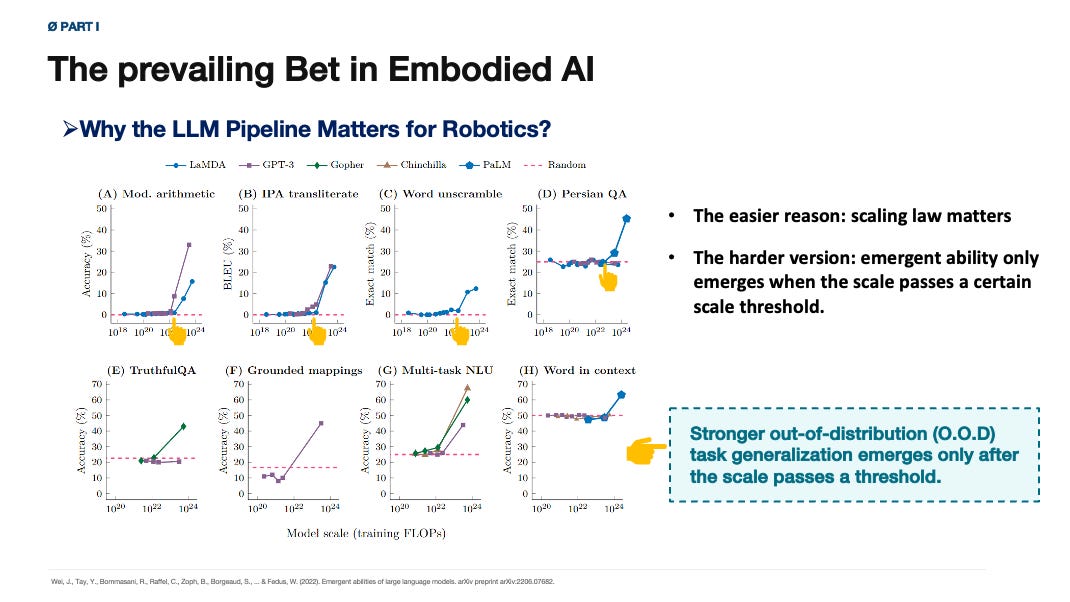
In NLP, the empirical case for such scaling behavior is much stronger than it is in robotics.
In computer vision it is already more unsettled.
In robotics it is even less established.
The reason OOD task performance matters so much in robotics is that small changes in the world can become large changes in the control problem.

A new object shape, a slightly different handle of the drawer, a changed lighting condition, a different gripper, a different compliance property of the manipulator, a shifted goal, a longer horizon, or a human moving through the scene can turn a familiar demonstration into an out-of-distribution task. Object variation, scene variation, embodiment variation, end-effector variation, task variation, instruction variation, and dynamics variation are not rare corner cases. They are the normal operating conditions of deployed robots.
This is where the analogy to NLP becomes fragile. A language model can encounter a new phrase, topic, or reasoning pattern, but the token interface remains stable. A robot encounters the world through sensors, actuators, contact, latency, calibration, friction, occlusion, and irreversible physical consequences. The “tokens” of embodied interaction are not just observations. They are actions in a world that pushes back.

My answer is therefore the following:
Robotics may inherit the pipeline shape of NLP -- pretraining, post-training, adaptation -- but not the same sufficiency condition. In robotics, pretraining and post-training are important, but they are not sufficient by themselves. The missing scaling axis is experience.
In embodied AI, pretraining should be understood as the beginning of capability, not its final form. Pretraining gives strong priors. But long-term embodied capability must continue to grow through interaction with the world.
I will try to develop this claim in four steps.
First, I will review the evolution of embodied AI models since 2022 which I view it as a search for scaling through more and better embodied data.
Second, I will introduce experience scaling as a different hypothesis other than the prevailing scaling hypothesis in embodied AI.
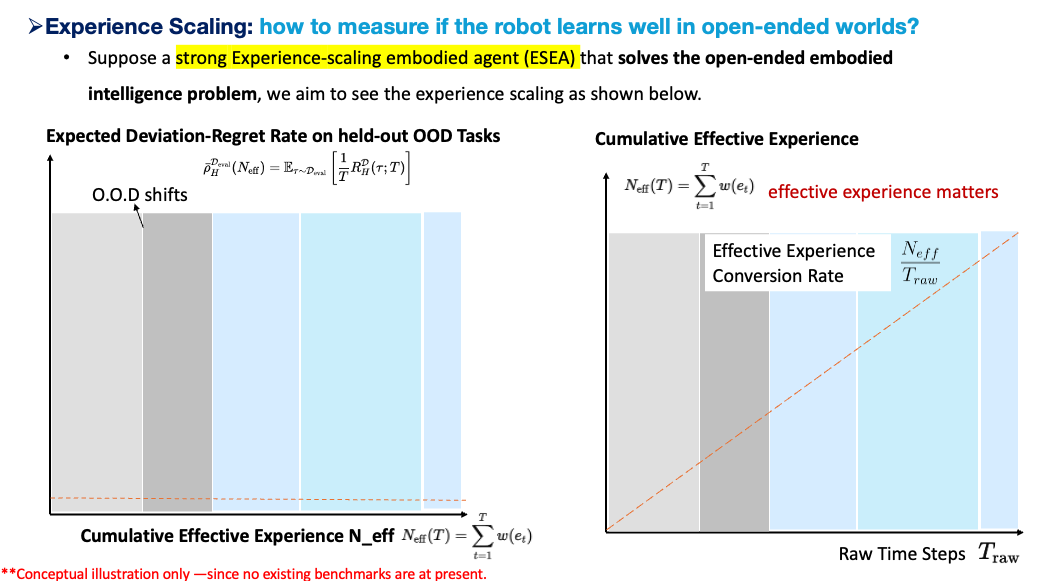
Third, I will explain how a held-out test for experience scaling should be constructed, and why existing benchmarks are close but not sufficient.
Finally, I will sketch the idea of an experience-scaling embodied agent: an agent that treats pretrained models as artifacts and converts embodied interaction into reusable skills under bounded resources.
In summary, I want to convey this idea as follows, which may not be new to many of you in embodied AI, but no one so far has explained it clearly: Pretraining gives priors. Experience gives growth.
II. The Evolution of Embodied AI Models Since 2022
To understand where embodied AI is going, I think we should read the last several years as a single story. That story is not merely that architectures became larger. It is also not merely that datasets became larger. The deeper story is that the field has been chasing a scaling-law-like regime for robotics, and that chase has repeatedly forced researchers to redesign both models and data pipelines:
The hidden driver is simple. In NLP, large-scale pretraining with large models and large datasets produced a regime in which scale translated into increasingly broad capability. Robotics researchers naturally asked whether embodied AI might follow the same path.
II.1 Phase 1: Fully End-to-End Generalist Ambition
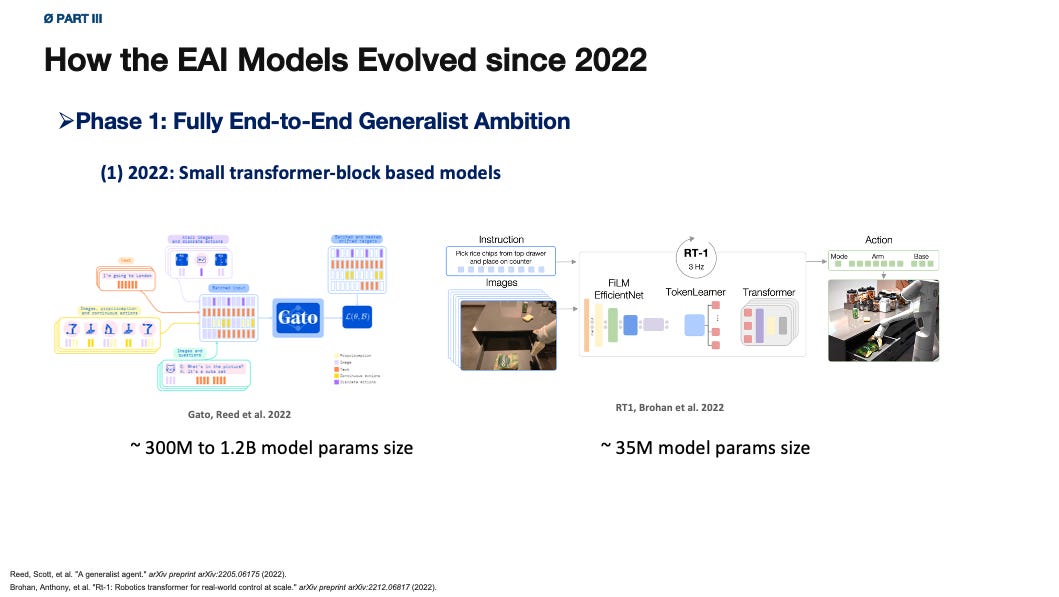
The first phase of recent embodied AI was an exploration of fully end-to-end generalist ambition. Gato, RT-1, and PaLM-E are natural representatives of this phase. These systems differed in architecture and scale, but they were driven by the same underlying bet: if scale worked in NLP models, perhaps scale could work in robotics as well.
Gato expressed one early version of this ambition: a single generalist agent trained across modalities, tasks, and embodiments, while its performance on robotic tasks is not that impressive yet, which may attribute to its model architecture that does not do clear modal alignment and does not carefully select more robot-relevant data. Anyway, Gato is the first presented general-purpose decsion-making agent, not specifically designed for robotics.
RT-1 from Google Everyday Robotics team made the ambition more robotics-grounded by showing the value of a small but more robotic-tasks relevant data will hugely improve the model’s performance in multiple robotic tasks. RT-1 showed that real robot data mattered enormously.
Another team from Google took a bold step and released a large model — PaLM-E — which was the first one showing large-scale embodied multimodal model pretraining, built on a language and vision backbone, could exhibits strong embodied reasoning and language understanding capability for robots. But it also exposed how difficult it is to turn a large backbone model into reliable, low-latency, contact-rich control.
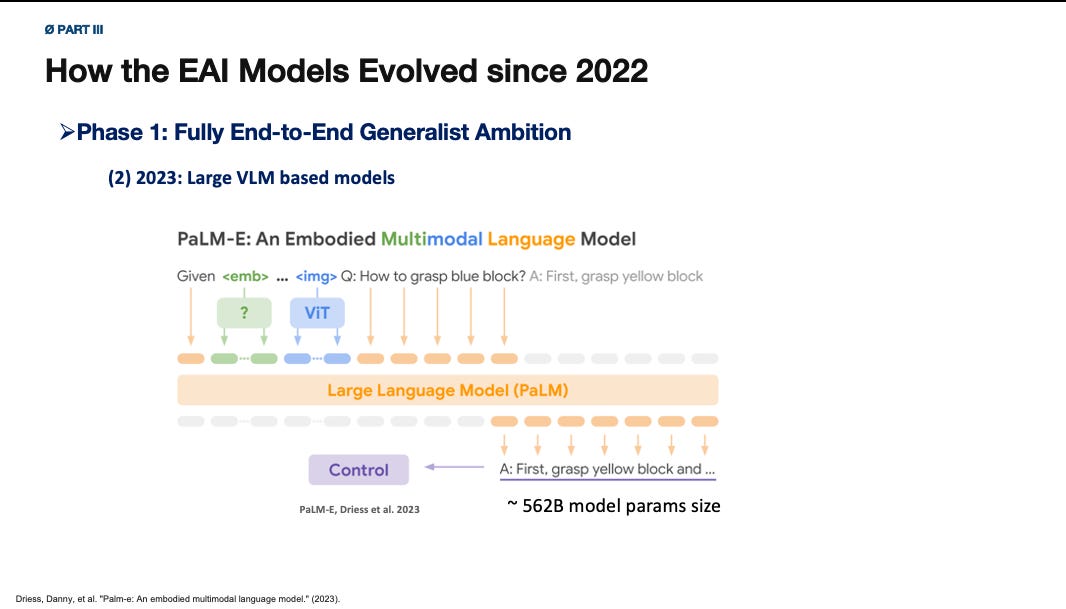
So the first lesson was not that the robotics scaling law had already arrived. The first lesson was that robotics can benefit from scale, but only under much harsher data conditions than NLP, for example, robot relevant data (DMC simulation data and KUKA grasping data in Gato, self-collected high-quality dataset in RT1).
This is the first place where data composition becomes central. In NLP, the interface is relatively stable: text tokens in, text tokens out. In robotics, the interaction signal is more expensive and more heterogeneous. The scaling question in robotics is therefore also a data-quality question, not just a data-quantity question.

II.2 Phase 2: The 0.5 End-to-End VLA Phase
The second phase can be read as a correction to the first phase.
Once the field saw that fully mixed end-to-end training was not enough, it reorganized the problem. The dominant solution soon became what I call the “0.5 end-to-end” phase: keep a strong pretrained vision-language (VLM) backbone, then add a robot-specific action-generation module that makes the problem as a conditional action distribution learning problem.
RT-2, OpenVLA, (\pi_0), and many excellent & related VLA models belong to this broader family, even if their action heads and training pipelines differ.
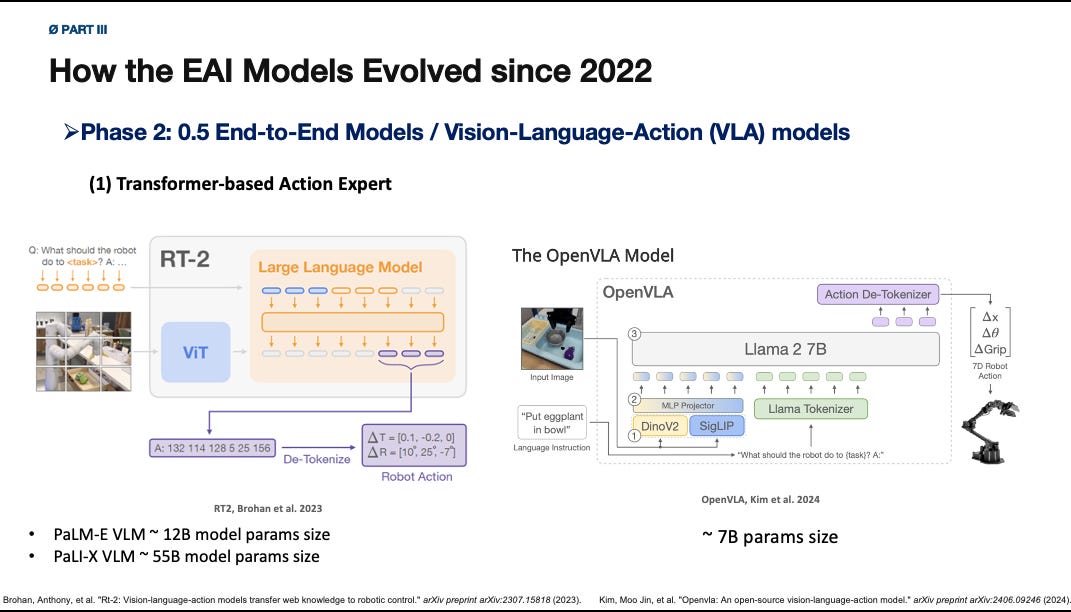
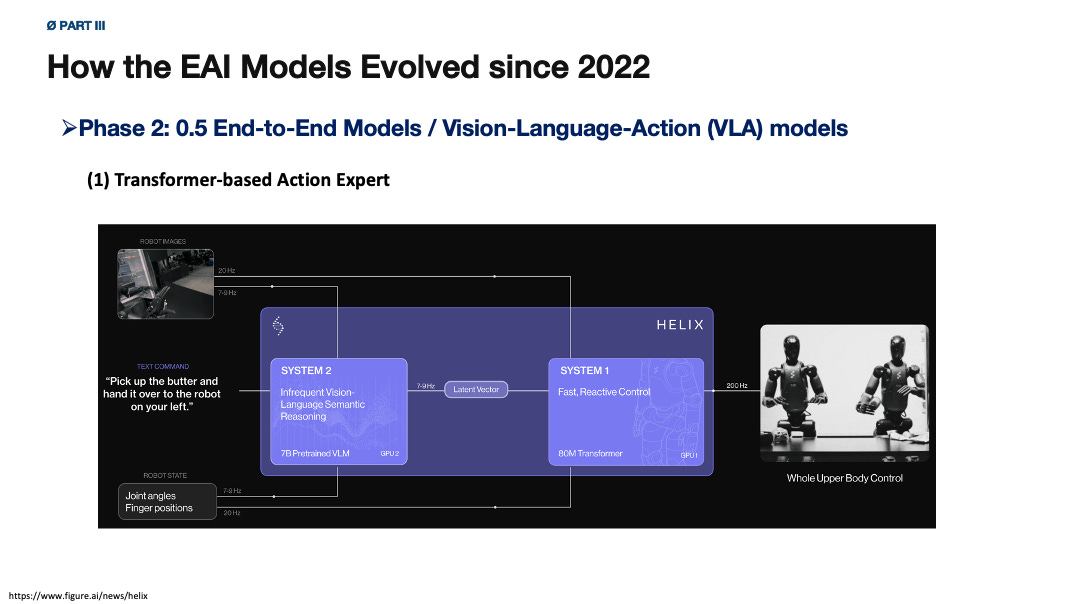
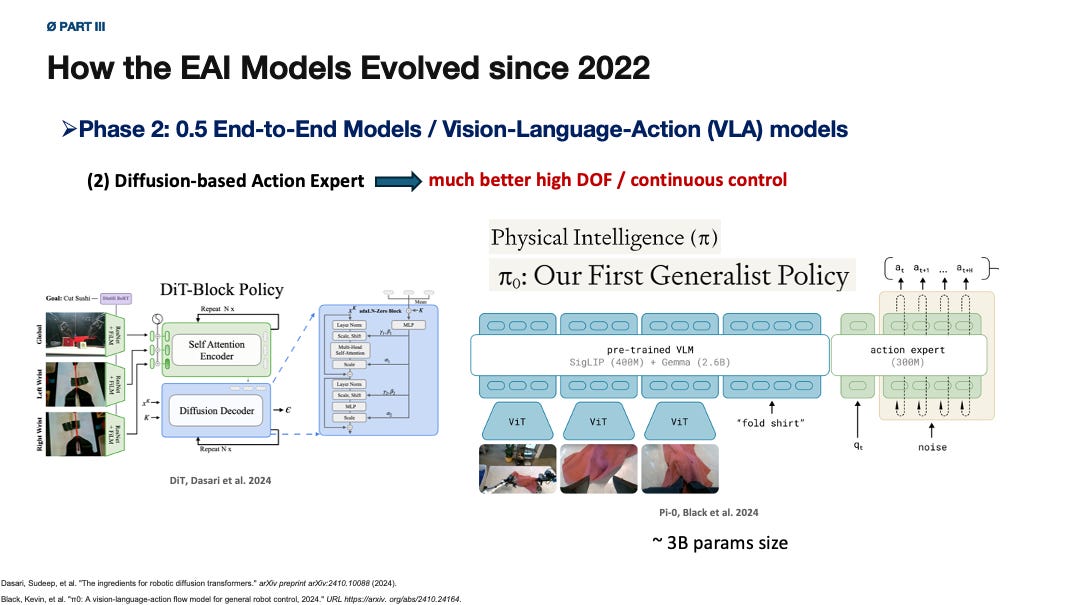
The VLA architectural logic is clear.
If real-world robot data matters so much, why not add a action-specific generation module and only fine-tuning this part using the real-world robot data. But, then how about language understanding, and visual-semantics grounding? Using a pretrained VLM!
So a pretrained provides semantic and perceptual structure. An action expert maps that structure to continuous or discretized actions. This design acknowledges that robot control needs specialized data while still trying to preserve the benefits of large-scale pretraining in the VLMs.

This will clearly introduce a second issue of the the VLM inside a VLA is not fully utilized for reasoning and language understanding, which I probably can talk about more later.
But VLA is efficient, and it significantly improves robotic task success rates.
Now, go back to VLA models.
In practice, to make VLA models even work better which achieves higher success rate in multiple robotic tasks, the field began asking a sharper question: does all real-world robot data matter?
This is where the VLA phase begins to become a real-world + high quality robot data competition phase.
And this is the beginning of data competition among EAI startup companies!
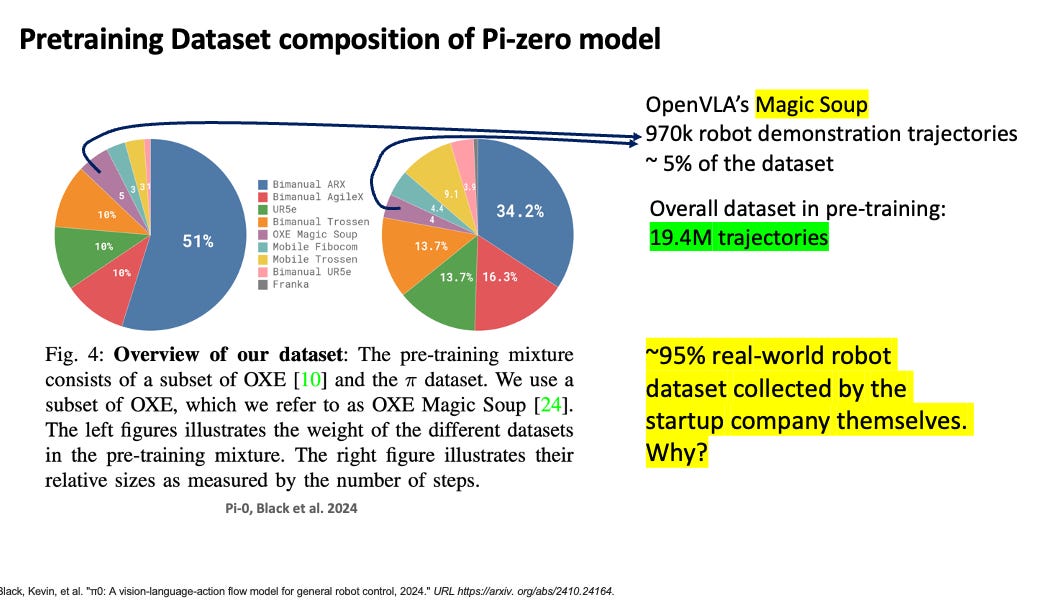
The field stopped treating all multimodal data as equally useful. It increasingly selected data that remain close to embodied control: robot demonstrations, cross-embodiment trajectories, robot-relevant visual supervision, and multimodal data that help with spatial reasoning, object grounding, or action selection.
Open X-Embodiment and RT-X should be read in this way: not merely as larger datasets, but as attempts to curate heterogeneous data that still carry robot-relevant structure.
This phase taught three lessons.
First, pretrained semantic structure is useful. It gives robot policies access to visual concepts, object categories, task language, and high-level priors that would be difficult to learn from narrow robot datasets alone.
Second, cross-embodiment transfer is real, but it often appears as stronger priors that needs further fine-tuning with your own robot’s dataset instead of plug-and-play deployment.
Third, high-quality robot data remain the critical scarce resource, which begins the EAI data competition.
At the same time, this phase exposed a new risk.
Once the field settled on “pretrained VLM plus action expert,” it became easy to imagine that the VLM solved the hard part and that action generation is merely an adapter. That is not what the evidence shows. The pretrained VLM’s language-vision modal alignment happens extensively in its cross-attention layers in multiple transformer blocks, however not conditioned on the current robotic tasks. And the latent output Z vector can not fully represent how a robot plans its actions based on the huge contextual information observed from multiple cameras, its joint/torque signals, and its past trajectories. It’s essentially a mis-alignment and information bottleneck problem that a VLA can not solve.
VLA systems still need substantial robot-data training, domain-specific post-training, and careful adaptation. Recent VLA models + domain-specific fine-tuning (SFT or RL) is a promising direction, but the cost is so high that if an EAI company wants to provide solutions for customer A’s scenario A1, a fleet of engineers will be required to collect specific data, post-training a specific model for A1, which is NOT a scalable business model for EAI startup companies.

The surviving mode for EAI startup companies, perhaps, is to find a scenario that has less unpredictable dynamic changes, so that the startup team can focus on it, and provide 99.5% coverage to all the possible envs in that scenario. If this is true, the market size will be bounded. But, can you find these scenarios?
Even if you can, it will turn to another dilemma, which relates to the “Wedge Strategy”, that a startup company can focus 100% of its resources on winning a tiny, highly specialized market first (the beachhead) before using that momentum to expand into a general solution.
But, the EAI tech development seems not ready for the general solution to arrive even when the business is ready to expand.
II.3 Phase 3: Beyond Robot Data and the Return of Richer End-to-End Models

Once the field realized that the key bottleneck was not only model size but interaction-relevant data, it had to ask a harder question:
Where can more usable embodied data come from? Where else can I get more robot-revalant data?

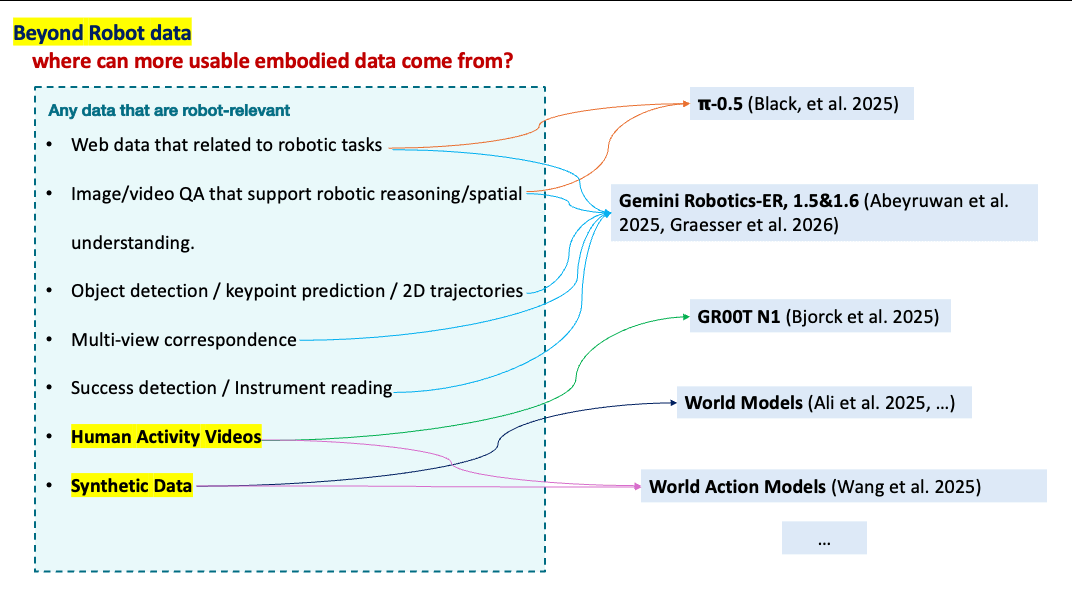
There are several answers.
Human activity videos may contain useful action structure. Synthetic data may expand visual and physical variation. World models may generate predicted futures and support planning or policy improvement. Embodied reasoning models may learn geometry, affordance, occlusion, contact, collision, success detection, and multi-view correspondence.
In all cases, the field is trying to expand the supply of data that are not necessarily robot trajectories, but are still robot-relevant.
This explains the recent interest in systems such as GR00T, Gemini Robotics-ER, (\pi_{0.5}), world models, and world-action models.
The point is not that all of these systems solve robotics. The point is that they represent a search for more usable embodied AI data.
If you can recall, in phase I, we have first tried mixed data that spans across the full spectrum of ML dataset, then in phase II we found robot data, then cross-embodiment robot data, and now increasingly tries all robot-relevant data.
Human video is attractive because it contains diverse behavior at scale. But human video does not become useful automatically. It must be mapped into robot-relevant action structure, for example through latent actions, inverse dynamics, keypoint trajectories, affordances, or other intermediate representations.
World models are attractive for a related reason. They may augment scarce interaction data, by predicting rare-case consequences, simulating variations, or supporting counterfactual planning. But a world model that predicts visually plausible futures without supporting reliable control is not enough. Since most world models are built based on latent actions, which infers the latent variable that drives the forward dynamics prediction (e.g., predicting future frames), it naturally can be extended to predict real robot actions, so that it can use robot trajectories during the training, which provides a new trend, world-action-models.
The rise of wold-action-models is not surprising, all due to the hunger of more EAI data and due to the belief that fully end-to-end models, compared to VLAs, are still the perfect solution for better generalization performances.
If readers are familiar with works that solves the cross-embodiment robot dataset co-training problem, which builds a latent action model that maps to different robot embodiment’s actions, they won’t be surprised to the claim that world models, world-action-models, actually do not differ too much, and actually they are a better version of fully end-to-end models compared the initial trials in the EAI community (e.g., PaLM-E).
Then, what’s the next BIG thing in Phase 3?
Continue the data hunger game, more robot-relevant data!
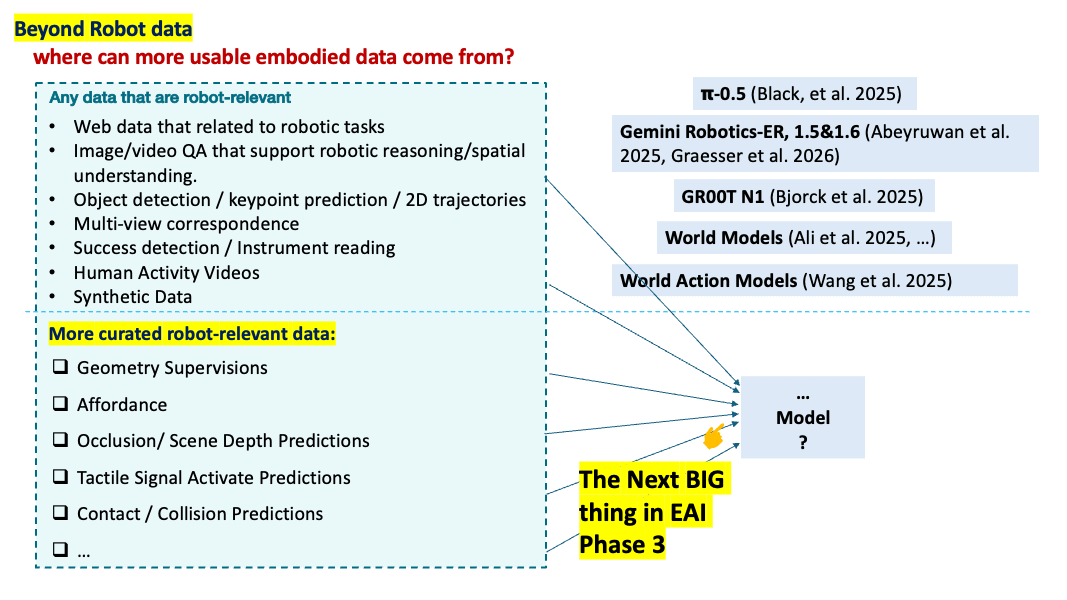
The predictive targets must be robot-relevant. Then how about more datasets on scene depth, task geometry, contact, occlusion, dynamics, object state, affordance, risk, and recoverability.
Model architecture will evolve again since world-action-models solves the unifying of human activity videos and robot trajectory dataset, but does not quite work in predicting more robot-relevant targets.
All the problem will essentially converge to (1) how to do modal alignment, (2) how to do multi-target training in one end-to-end unified model.
This is why the return of richer end-to-end models is not a return to the naive version of Phase 1. The field is trying to build models that can absorb heterogeneous robot-relevant data while still supporting control.
II.4 The Hidden Line: Chasing Scaling Through EAI Data
At this point, the history can be summarized in one line:
The history of embodied AI since 2022 is the history of a field chasing a scaling regime for robotics, and therefore repeatedly redesigning both models and data pipelines in search of more usable embodied AI data.
Once we read the history that way, the sequence becomes coherent.
Phase 1 tried fully mixed end-to-end models.
Phase 2 discovered that high-quality robot data matter more than indiscriminate multimodal scale and moved toward VLA architectures.
Phase 3 discovered that even high-quality robot data are too scarce, and began reaching toward cross-embodiment robot data, human activity video, synthetic data, world models, geometry supervision, affordance prediction, contact prediction, and embodied reasoning tasks.
This year of 2026 will still be in Phase 3. While post-training techniques like RL will rise, compared to the universally capable base model training, these techniques are less important.
Every major turn is pulled by the same desire: to find a scaling regime in robotics where more data, more compute, and larger models reliably translate into broader robotic task mastering capability.

5 The Unresolved Scaling-Law Question in Robotics
The unresolved issue is that we still do not know how large is large enough.
We do not know how many robot trajectories, embodiments, objects, tasks, failure cases, human corrections, dynamics regimes, or synthetic variations would be needed to cross a true scaling threshold for open-world robotic task generalization.

A trillion language tokens and a trillion embodied interaction tokens are not equivalent. A language token stream is not a force-bearing, contact-rich, embodiment-specific interaction history. A robot trajectory is not just a sequence of observations. It is a record of actions taken under a particular body, controller, calibration, scene, object distribution, and dynamics regime. Its relevance to another robot, another object, or another environment is always conditional.
This is where the Big World Hypothesis (BWH) becomes important.
The hypothesis says that for many learning problems, the world is much larger than the agent. The agent cannot fully observe the state of the world, cannot store everything, and cannot compute optimal actions for every possible state. It must rely on approximate solutions under bounded resources.


Robotics is a natural big-world domain. The physical world is combinatorial, partially observed, path-dependent, and nonstationary. New objects, layouts, materials, tools, users, preferences, and failures appear continually. If this diagnosis is right, then the problem may not be that robotics has simply not yet reached a large enough static pretraining scale. The problem may be that static coverage is the wrong ideal.
The field’s hunger for more data is therefore understandable under the BWH. The field has learned that scale helps. It has learned that heterogeneous data help. It has learned that cross-robot and cross-task transfer helps too. But it has not established that static pretraining alone closes the open-world generalization gap.
In my opinion, even post-training techniques (SFT/RL) can not be the rescue. I will explain in the next section.
If the history of embodied AI is the history of chasing scaling through ever more usable embodied data, perhaps the missing scaling axis is not just data. Why not just embracing the continous changing open-ended world itself? Perhaps the missing scaling axis is experience itself.
III. Experience Scaling as a Different Hypothesis
If static pretraining is not sufficient, the conclusion is not that scaling is useless. The conclusion is narrower and more serious: the field has not shown that static pretraining alone can deliver open-world embodied intelligence.
That raises the next question. If scaling data, models, and compute is not the whole story, what is the missing scaling axis?
My answer is: experience.
I am not arguing that pretraining should be abandoned. I am arguing that it should be repositioned.
In embodied AI, pretraining is best understood as the source of strong priors, not as the final source of its strong OOD task generalization performance. The long-term capability of an embodied agent must continue to grow through its own interaction with the world.
Will post-training techniques like SFT or RL be the rescue? Well, I doubt that. SFT and RL post-training are not a satisfactory general solution because they are difficult to scale across continually changing OOD shifts, which is quite common in real world when human perform varies tasks.

III.1 What Counts as Experience?
An embodied experience is not merely a frame, or a token. It is a closed-loop transition in which the agent observes, acts, receives next consequential observation, pays costs, and may receive feedback or correction. A useful abstraction is
where (o_t) is the observation, (a_t) is the action, (o_{t+1}) is the next observation, (r_t) is reward or outcome feedback, (h_t) is human correction or instruction when available, (c_t) is resource cost, and (\delta_t) is a learning signal such as prediction error, novelty, uncertainty, or regret.
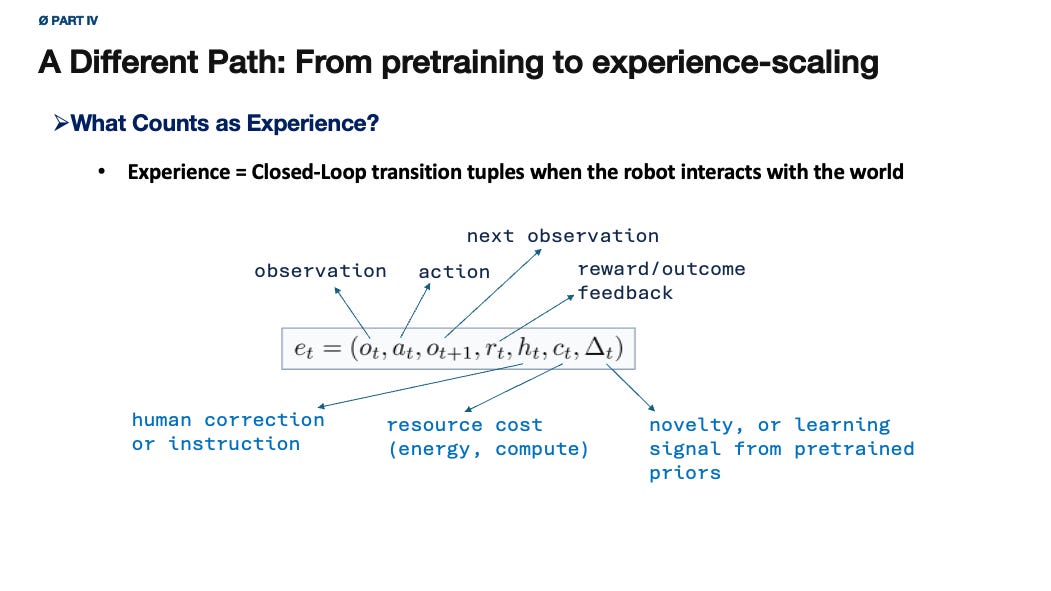
This definition is deliberately broader than standard reward-based RL.
Real robots often learn from sparse success signals, human corrections, failed attempts, recovery trajectories, constraint violations, prediction errors, or changes in human preference.
The important point is that embodied learning is feedback-coupled. The data distribution is not just given to the agent. The agent helps create it through action.
III.2 Effective Experience: Not All Interaction Is Useful
If experience is the scaling axis, then raw interaction count is not enough. Why?
Ten thousand repeated easy successes may add little useful information.
One failure followed by a human correction, a recovery trajectory, and an update to the skill library may add much more.

This motivates the notion of effective experience:
where (w(e_t)) measures how much interaction (e_t) contributes to future reusable capability.


High-value experience may involve novelty, bottleneck states, subproblem discovery, failure recovery, human preference updates, prediction correction, or skill refinement.
Low-value experience may be redundant execution that produces no change in policy, memory, representation, reward model, world model, or skill library.
This distinction is important to me.
Experience scaling is not simply scaling the amount of experience. It is scaling the amount of reusable structure extracted from experience.
The x-axis of an experience-scaling law should therefore not be raw time steps alone. It should be cumulative effective experience.

A strong embodied agent should convert a large fraction of its interaction stream into useful updates. A weak agent may accumulate many steps while learning very little.
III.3 Experience Scaling: the held-out test for open-ended EAI
(1) We should not set task boundaries in EAI benchmarks.
A major problem in continual learning and robot learning is that benchmarks often organize evaluation around tasks with explicit boundaries. A task starts. A task ends. A task ID may be known. The environment may reset. A success predicate is defined. The agent is evaluated, then moved to the next task.
This structure is useful for experimental control. But it also gives the agent, or at least the researcher, information that a deployed robot usually does not have.
Task boundaries are a kind of oracle context. They say: something has changed; the previous episode is over; the evaluation unit has reset; the relevant success predicate is now this one.
In real deployment, changes are often seamless.
A person moves an object.
A tool wears down. Lighting changes.
A handle becomes slippery.
A user changes preference.
A new object appears next to an old one.
The robot may not receive a task ID or a change-point label. It must infer from its own history whether it is facing the same latent context, a modified context, a recurring context, or a genuinely new context.
Under the Big World Hypothesis, this matters. The agent is smaller than the world, and the world will not package itself into clean tasks for the agent’s convenience.
If a robot that only adapts when a benchmark tells it that a new task has started is not solving the deployment problem. It is solving a cleaner problem.
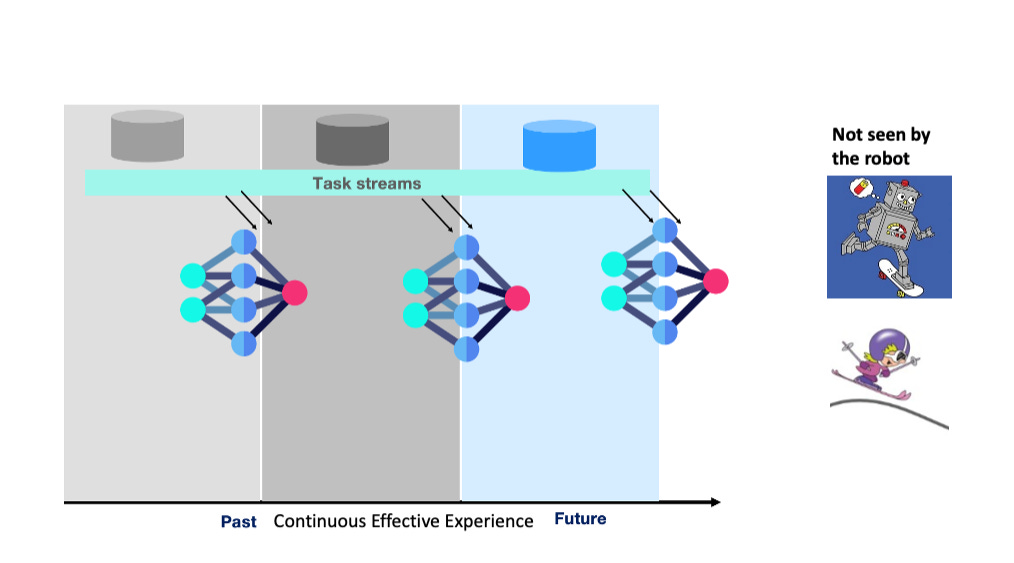
This is why task-boundary-free evaluation is important. The goal is not to make benchmarks unnecessarily hard. The goal is to avoid giving the agent side information that removes the central difficulty of continual embodied learning: detecting, interpreting, and adapting to latent context changes while acting.
(2) Why continuous adaptation matters?
Continuous adaptation is important for three reasons.
First, physical deployment is nonstationary.
The state distribution, dynamics, goals, preferences, and constraints can change over time. Some changes are abrupt; many are gradual. A robot that only performs offline adaptation before deployment will eventually become miscalibrated.
Second, errors accumulate.
In episodic benchmarks, a reset often erases the consequences of earlier mistakes. In real-world operation, a bad grasp can move an object into a worse configuration, a missed collision can damage a tool, and a wrong assumption about a user’s preference can affect later interaction. Recovery is not a secondary behavior. It is part of the EAI model’s capability.
Third, future task performance depends on what the agent chooses to learn from. The subtask discovery problem!
In a big world, the agent cannot store or update on everything. It must decide which failures, corrections, state changes, and predictions are worth converting into memory, skills, or model updates. Continuous adaptation is therefore not just online fine-tuning. It is resource-bounded management of a lifelong learning process.
This is the key shift:
The object of study should not only be a policy trained on a task distribution. It should be an agent interacting with a nonstationary history process.
(3) How to construct a held-out test for experience scaling?
If experience scaling is a real hypothesis, it needs a serious evaluation protocol.
In supervised learning and NLP, a held-out test set is relatively easy to define. We hold out examples from a distribution and evaluate whether performance improves with the model/dataset scale.
In embodied AI, the corresponding design is more difficult. A robot does not only predict labels. It acts, changes the world, receives feedback, and creates its own future data distribution.
So the held-out test for experience scaling should not be only a list of tasks. It should be a held-out interaction process.
Let’s firstly define it before we build it.
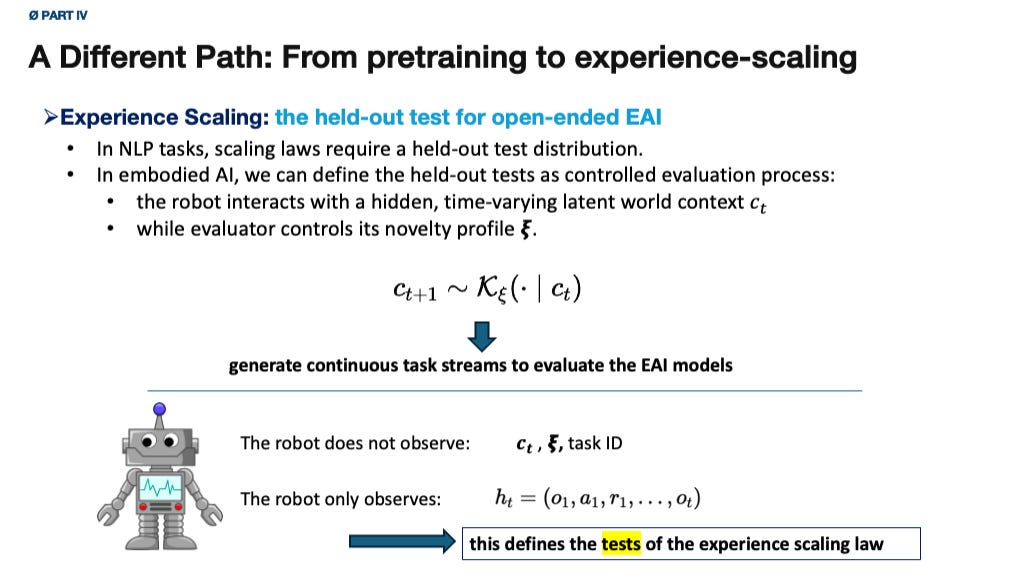
(4) The Latent Context \xi_t and Novelty Profile \nu_t
Since we are designing the benchmark world for the EAI agent, we can play the role of the world creator. From an oracle view, let the world at time (t) be governed by a hidden context
where
(\mathcal{O}_t) represents world objects and their properties,
(\mathcal{L}_t) the scene layout,
(\mathcal{D}_t) the dynamics,
(\mathcal{B}_t) the embodiment and controller state,
(\mathcal{G}_t) the goal or task semantics,
(\mathcal{P}_t) human preferences,
and (\mathcal{S}_t) sensors and observations.
\xi_t can be more complex, simulator designers (e.g., BEHAVIOR 1k designers) may know much better than me. Anyway, \xi_t just define the world context at time t.
The agent does not observe (\xi_t) directly.
It observes only its sensor stream, instructions, feedback, and internal memory.
The evaluator, however, controls how (\xi_t) changes over time through a novelty profile .
This novelty profile specifies when and how OOD shifts occur: object shifts, layout shifts, dynamics shifts, embodiment shifts, preference shifts, task-composition shifts, or combinations of these.
The evaluation distribution is therefore not just p_test(task). It is a distribution over context histories:
This is the first key design principle:
The evaluator should hold out a history process, not just a task set.
This is where the evaluation differs from ordinary OOD generalization. The question is not only, “Can the robot solve a new task?” The question is:
Can the robot use its own past interaction to reduce future regret under hidden, changing context?
To test experience scaling properly, the robot should not observe the latent context (\xi_t), the novelty profile (\nu_t), the task ID, or the change points. It may receive natural instructions, sensor observations, sparse success signals, human corrections, and safety interventions. But it should not be given the clean boundary labels that make continual learning artificially easier.
III.4 Deviation-Regret as a Task-Boundary-Free Error
If the evaluation stream has no clean task boundaries, then success rate per task is not enough. We need an error measure that can be computed along a continuous stream.
One useful candidate is deviation-regret. In Elelimy et al. 2025, the Rethinking Foundations of Continual RL, they define the derivation regret for a continual learning agent as follows:

We can follow the same definition, but the tricky part is the \phi (derivations) at time t as it’s often unknown. Here, we can treat \phi (derivations)’s coutcomes as all available policies present to the evaluator, e.g., pretrained VLAs best for this specific task, world models best for this task, a predefined recovery policy, a predefined controller etc., which are easy to obtain on the evaluator side since we are playing the God.
Next, we define the deviation-regret formally for EAI tasks.

At time (t), the agent follows its current policy (\pi_t).
The evaluator has access to a set of possible deviation operators (\mathcal{D}).
A deviation operator may replace the current policy with a better local controller, a pretrained VLA specialized for the current context, a recovery policy, a world-model planner, a human correction, or another available intervention.
Each deviation operator (d \in \mathcal{D}) produces an alternative policy (d(\pi_t)).
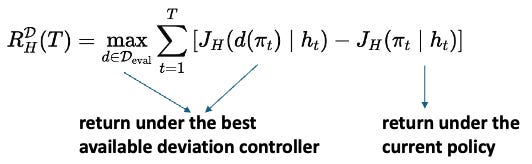
Let (J_H(\pi_t; h_t)) be the local (H)-step return from the current history (h_t). The deviation-regret over a stream of length (T) can be written as
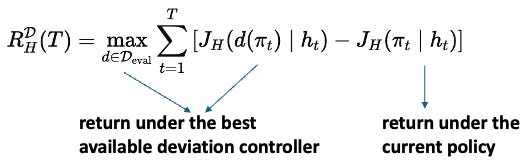
The expected deviation-regret rate is then

This measures how much the agent loses by not using the best available systematic intervention at each point in the stream.
This gives the y-axis of an experience-scaling curve: expected deviation-regret rate on held-out OOD streams. In summary:

III.5 Will Existing Benchmarks Work?
Existing benchmarks are valuable, but they are not yet enough.
LIBERO is an important benchmark for lifelong robot learning and knowledge transfer. It explicitly studies declarative and procedural knowledge transfer in robot manipulation and includes task suites that vary objects, spatial arrangements, goals, and their mixtures. That makes it highly relevant. But it is still organized as task suites. The agent is evaluated on defined manipulation tasks, and the task structure is more explicit than what we should expect in open-ended deployment.
BEHAVIOR-1K is also highly relevant. It contains 1,000 human-centered household activities, realistic scenes, long horizons, and complex mobile manipulation. It is closer to the diversity of tasks people actually want robots to perform. But it is still activity-defined. The unit of evaluation is an activity instance, not a seamless stream of latent context changes.
ARC-AGI-3 is especially interesting because it moves beyond static puzzle solving into interactive reasoning. Agents must explore novel environments, infer goals, build internal models, and adapt without natural-language instructions. It also uses held-out interactive environments, which makes it closer in spirit to experience scaling than many static benchmarks.
But ARC-AGI-3 is still not the same as the experience-scaling benchmark needed for embodied AI. Its environments are bounded game-like units. They have implicit task or game boundaries. They are abstract and turn-based, not physical, contact-rich, resource-bounded, or embodiment-specific. Most importantly, they do not fully test seamless changes among tasks under a continuous embodied history. ARC-AGI-3 is a strong step toward interactive evaluation, but it is not a benchmark for task-boundary-free robotic adaptation in the big world.
A future benchmark should combine the strengths of all three directions:
the lifelong transfer structure of LIBERO,
the long-horizon human-centered benchmark task designs of BEHAVIOR-1K,
and the hidden interactive adaptation test of ARC-AGI-3.
But it must add what they still lack: continuous latent context drift, no task IDs, recovery from self-induced errors, resource budgets, human corrections, and evaluation over a held-out history process. I did not see any EAI benchmarks incorporate these design, but I hope to see them in the future.
IV. Is RL Post-Training a Rescue?
A natural response to the previous sections is: perhaps pretraining is not enough, but reinforcement learning will solve the rest. This is especially natural now because RL for VLA models has become a major direction. If LLM post-training used RL or RL-like objectives to improve reasoning and instruction following, perhaps VLA post-training with RL can similarly improve long-horizon robotic control.
I think RL is important. But I do not think RL, as it is usually framed today, is a scalable rescue for open-world embodied AI.
IV.1 How RL with VLA Models Works
A pretrained VLA model usually starts from supervised imitation. It learns a policy
where (o_{\leq t}) is the observation history and (\ell) is a language instruction or task specification.
RL post-training adds an interactive update stage. The policy is rolled out in a simulator, a real robot environment, a benchmark suite, or a world-model-generated environment.
The system receives rewards, success/failure signals, human corrections, or value estimates. The policy is then updated using a policy-gradient method, advantage estimation, residual RL, advantage-conditioned supervised learning, or another RL-style objective.
Recent VLA+RL work follows this general pattern. Some methods use sparse binary success rewards to fine-tune pretrained VLAs. Some use scalable rollout sampling and parallel environments. Some collect real-world autonomous rollouts and human corrections. Some use world models as controllable simulators for reinforcement fine-tuning.
The common idea is that a pretrained VLA already contains useful visuomotor priors, and RL can unlock or specialize those priors for target tasks.
This is a real advance. RL can reduce compounding errors from imitation learning. It can exploit task success signals that are not present in demonstrations by combining sub-trajectories effectively, as demonstrated in recent paeprs. It can improve long-horizon behavior when supervised fine-tuning is limited. It can adapt a strong prior to a target environment.
IV.2 Why RL Helps Locally
RL helps because imitation learning is limited by the demonstrations it sees. A supervised policy can learn to reproduce expert actions, but it may fail under distribution shift, accumulated errors, or new object configurations.
RL allows the policy to learn from its own rollouts. It can discover that an action sequence succeeds even if it is not exactly in the demonstration set. It can use sparse rewards to select among latent behaviors already present in the pretrained policy. It can improve recovery behavior when the robot drifts away from expert states.
This is especially valuable for VLA models. A large VLA may contain many latent visuomotor skills, but the model may not know how to deploy them reliably for a new task.
RL post-training can sharpen the action distribution, improve credit assignment, and specialize the model to a particular environment or task family.
So the local case for RL is strong: RL can improve a pretrained embodied policy within a controlled interaction distribution.
IV.3 Why RL Is Not a Scalable Rescue by Itself
The difficulty is that general-purpose robotics is not a single controlled interaction distribution. It is a large, diverse, non-stationary family of partially observed control problems.
RL post-training does not scale automatically across this diversity for several reasons.
First, rewards do not come for free. Many robotic tasks require success detectors, preference models, safety constraints, or human judgments. A sparse binary reward may work for a benchmark task, but open-world deployment requires deciding what counts as success under changing goals, changing users, and changing contexts.
Second, exploration is expensive and risky. In simulation, the agent can try many rollouts. In the real world, failed rollouts can damage objects, waste time, require resets, or create unsafe states. World models can reduce this cost, but only if their predictions are reliable for the relevant contact, geometry, and dynamics scenarios.
Third, task boundaries are often assumed. Many RL post-training pipelines fine-tune on a known task, a known benchmark suite, or a known environment distribution. This is useful, but it is not the same as discovering when the task has changed, what has changed, and whether a new skill should be created.
Fourth, per-task fine-tuning is not a scalable solution to general task solvers. If every new object, layout, preference, or dynamics shift requires a separate RL phase, then the approach becomes a collection of local adaptations rather than a theory of general-purpose embodied growth.
Fifth, RL updates can interfere with earlier learned task skills. A policy improved for one context can degrade in another. Without memory management, skill modularity, and retention criteria, RL becomes another source of instability.
Sixth, RL often optimizes expected return in a defined MDP or POMDP, but the big-world problem is better viewed as persistent adaptation under hidden context drift. The agent must minimize regret while detecting context changes, managing resources, and deciding what to remember.
This is why I do not view RL post-training as a rescue.
IV.4 Static Pretrained Models, RL Post-Training, and Strong ESEA
This distinction becomes clearer if we compare three representative systems.
A static pretrained EAI model can have strong jumpstart performance. It may solve many tasks immediately because it has learned strong priors from robot data, web data, human video, synthetic data, and multimodal supervision. But if its parameters, memory, and skill library do not update through deployment, then its effective experience conversion rate is low. Its regret may remain low on familiar contexts, but OOD shifts can cause large spikes. The model’s ceiling is mainly fixed by its pretraining distribution.
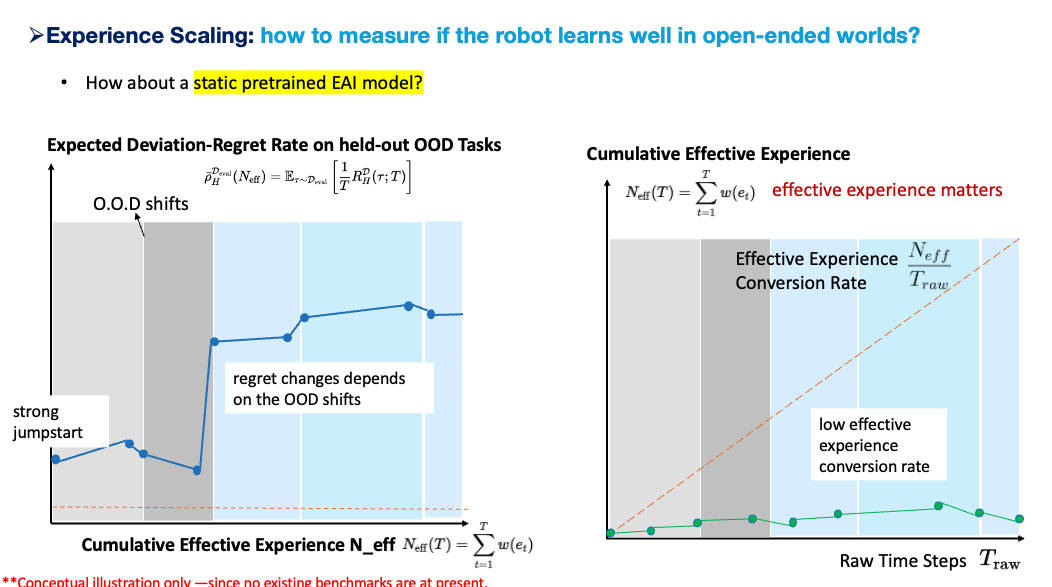
A post-trained RL VLA improves on this. It can collect rollouts, use sparse rewards or corrections, and adapt to a target task family. Its regret may drop after a post-training phase. It may recover from some imitation errors and become more robust within the fine-tuning distribution. But if the RL stage is tied to explicit task boundaries, known rewards, resettable environments, or per-task adaptation, then it still does not scale to seamless open-world diversity. It improves after being told where and how to improve.
A strong experience-scaling embodied agent should behave differently. It should start with pretrained priors, but it should also detect novelty, identify bottlenecks, ask for correction when needed, select useful artifacts, update memory, refine existing skills, discover new skills, and manage resources. When an OOD shift occurs, its regret may spike, but the spike should be smaller and shorter over time. More importantly, the agent should convert the event into reusable structure. A failure under a new object should not only improve that one object interaction; it should refine an affordance, a recovery skill, a contact model, or a memory item that helps future tasks.
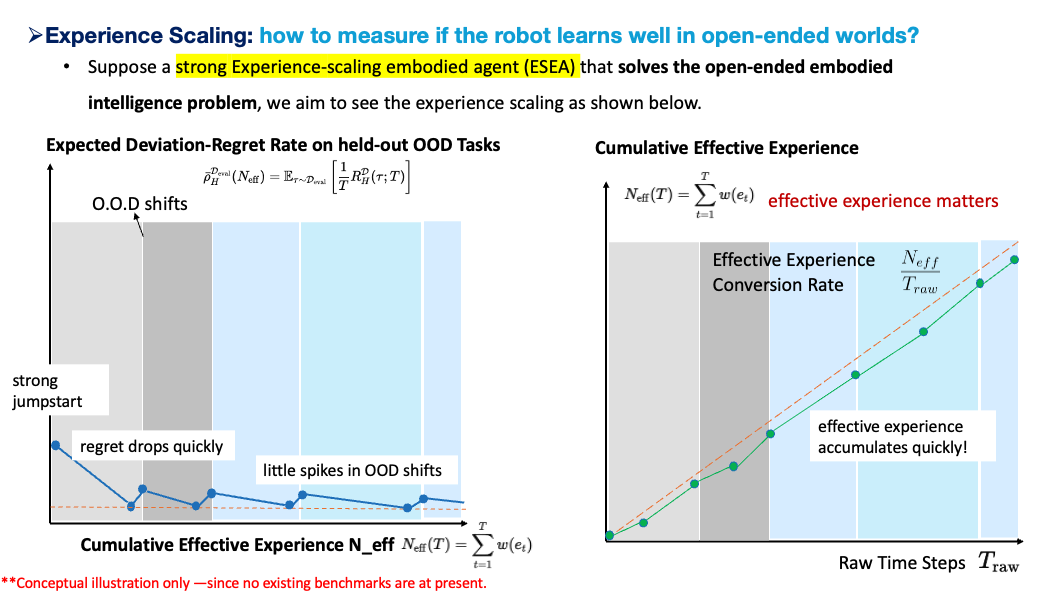
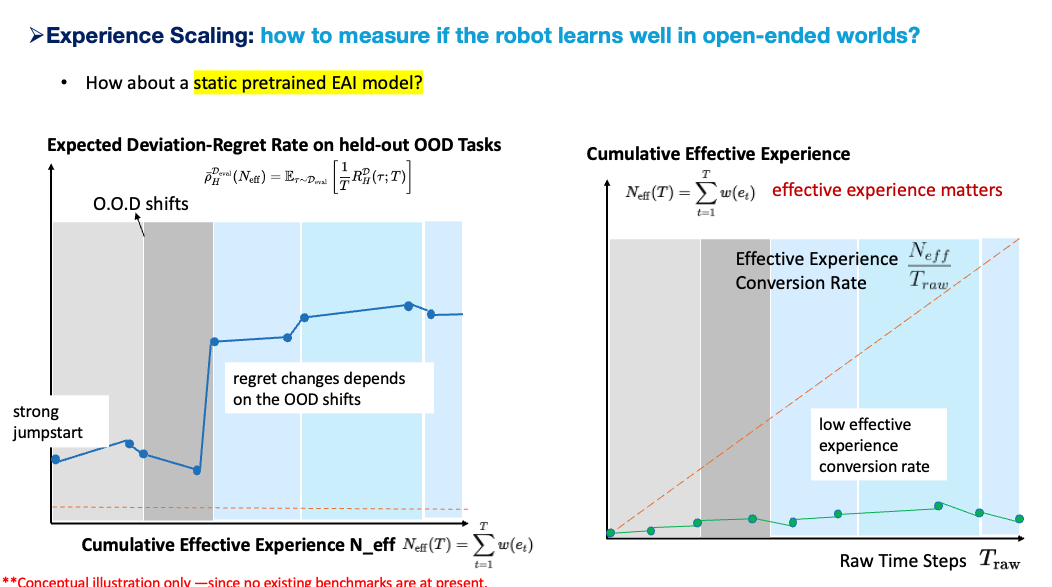
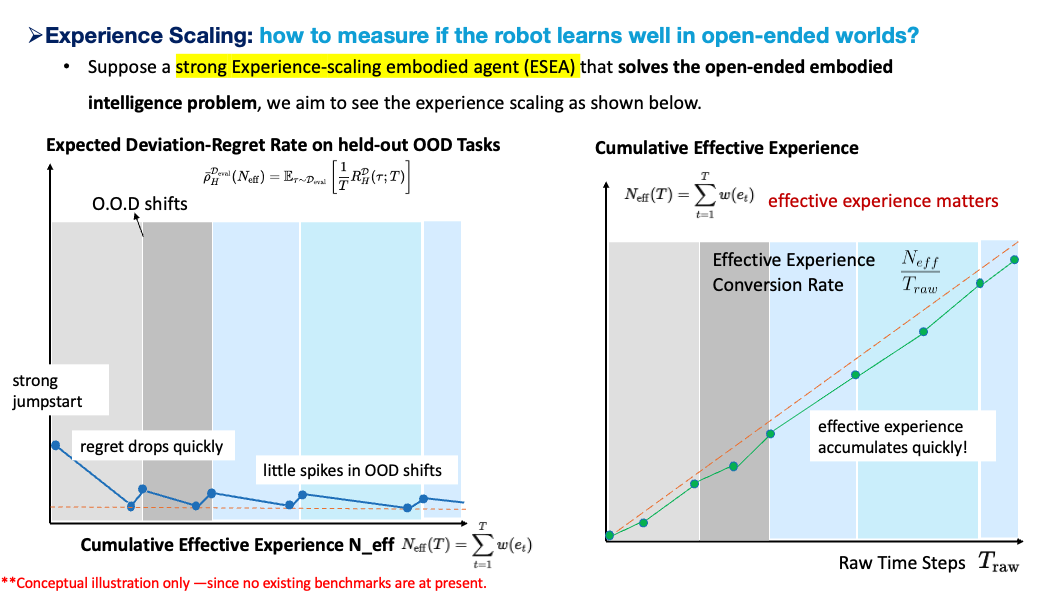
This gives a more precise interpretation of strong experience scaling:
A strong ESEA is not merely an agent whose final success rate improves. It is an agent whose effective experience conversion rate is high, whose deviation-regret decreases on held-out OOD streams, and whose learned structure remains reusable under future context changes.
IV.5 What RL Should Become Inside ESEA
Inside an experience-scaling embodied agent, RL still has a central role. But that role changes.
RL should not be treated only as downstream fine-tuning. It should be one mechanism for converting experience into reusable structure.
Sometimes RL updates a policy.
Sometimes it trains a value function. Sometimes it selects among skills.
Sometimes it refines a recovery behavior.
Sometimes it estimates the usefulness of an external artifact.
Sometimes it decides which memory items to keep because they reduce future regret.
In this view, the key RL objective is not simply to maximize return on the current task.
The key objective is to reduce future deviation-regret under bounded resources.
That objective is closer to continual decision-making than to one-time post-training.
So the right question is not:
Can RL rescue pretraining?
The better question is:
How should RL be embedded inside an architecture that scales through effective experience?
V. Foundation Models as Cognitive Artifacts
The experience-scaling view does not exclude foundation models. It assigns them a more nuance role.
A useful way to think about this is through the idea of artifacts and external memory.

Environmental artifacts can reduce the amount of internal information an agent needs to represent history and act competently. A map, a written note, a tool, a simulator, a database, or another model can function as memory or computation outside the agent’s immediate parameters.
Pretrained foundation models can be interpreted in the same way. They are not necessarily the agent itself. They are cognitive artifacts available to the agent.
A VLM can be a semantic and perceptual library. It helps identify objects, relations, affordances, instructions, and visual context.
A VLA can be an action prior or skill initializer. It gives the agent a strong initial policy over robot-relevant actions.
A world model can be a predictive artifact for planning, safety filtering, counterfactual testing, and subtask proposal.
An LLM can support language interaction, task decomposition, self-critique, and memory retrieval.
A simulator can provide low-risk exploration when its domain is trustworthy.
This view resolves a tension.
Pretrained models now provide priors, abstractions, predictions, and sub-task proposals. The correct way of thinking this problem, perhaps is:
Once we view pretrained models this way, pretraining becomes the beginning of embodied capability rather than its endpoint.
VI. The Experience-Scaling Embodied Agent
The architecture implied by this discussion is an Experience-Scaling Embodied Agent, or ESEA.
An ESEA is an agent architecture that converts embodied interaction into reusable skills under resource constraints. A useful abstract tuple is
where (\theta) is the onboard policy and representation, (\mathcal{M}) is the memory and skill library, (\mathcal{E}) is the set of external artifacts such as LLMs, VLMs, VLAs, world models, simulators, retrieval systems, and symbolic tools, and (\mathcal{R}) is the resource budget: compute, memory, latency, energy, safety risk..
A concrete ESEA, IMHO, needs at least six functions.
First, it needs an embodiment interface. The agent cannot abstract away from body, action space, latency, calibration, safety constraints, and control frequency.
Second, it needs an artifact interface. The agent must know when and how to use VLMs, VLAs, LLMs, world models, simulators, retrieval systems, controllers, and human feedback.
Third, it needs a predictive interaction backbone. The agent must model how actions change observations, object states, uncertainty, risk, and future affordances.
Fourth, it needs a skill discovery and refinement mechanism. It must turn interaction into options, subgoals, recovery routines, preconditions, effects, and capability estimates.
Fifth, it needs memory consolidation and forgetting. It cannot store everything. It must decide which experiences, skills, and representations reduce future regret enough to justify their resource cost.
Sixth, it needs a meta-controller. It must decide when to act, when to explore, when to ask for help, when to call an artifact, when to update a skill, and when to avoid unsafe learning.
VII. Why Skill Discovery, Memory, and forgetting Are the Missing Mechanisms
I think currently, skill discovery and memory are the most urgent research goals.
(1) About skill discovery
A robot does not scale through experience merely by updating weights. It scales when it transforms interaction history into reusable behavioral abstractions.
That is why skill discovery is important. The agent must discover subproblems, options, bottleneck states, recovery behaviors, controllable variables, and reusable action patterns. It must refine skills through practice and correction. It must consolidate skills into memory. It must forget or compress skills that no longer reduce future regret.
New skills can come from several sources.
They can come from controllability: discovering parts of the world the agent can reliably influence, as demonstrated in several classic RL papers.
They can come from bottlenecks: states that make many future tasks easier once reached.
They can come from failure: repeated regret patterns that reveal a missing subskill.
They can come from human correction: interventions that expose violated preferences or missing subgoals.
They can come from external artifacts: candidate decompositions, affordances, action proposals, or recovery plans generated by pretrained models and then tested in the real world.
This point is important because it prevents experience scaling from becoming vague. The agent does not simply “learn more.” It converts interactions into reusable structures.
(2) About memory and forgetting under resource bounds
In many continual learning papers, forgetting is treated mainly as a bug.
For embodied agents, that view is incomplete.
A real robot is bounded in memory, compute, energy, and time. It cannot preserve everything. It should not preserve everything.
Some memories are obsolete. Some skills are redundant. Some context-specific policies are harmful outside their context. Some stored experiences cost more to retrieve and maintain than they contribute to future capability.
A useful retention criterion is:
A memory item, skill, or representation should be kept if its expected reduction in future regret exceeds its resource cost.
This turns forgetting into resource allocation rather than a designing bug.
Strategic forgetting is therefore part of experience scaling. The agent must preserve plasticity while retaining useful structure.
VIII. Why Current Continual RL Is Still Not Ready
Experience scaling sounds close to continual reinforcement learning. That is not a coincidence. Continual RL is probably the closest formal home for this problem.
But current continual RL is not yet enough.
The problem is not that continual RL is unimportant. The problem is that much of it still studies a cleaner problem than the one real embodied agents face. It often assumes clearer task boundaries, stronger resets, more repeatable episodes, more explicit reward definitions, less dependence on artifacts, and less pressure from bounded resources.
The mismatch can be summarized by five contradictions.

IX. Open Research Questions
The experience-scaling view suggests a research program rather than a single algorithm.
The overall question is:
How can we build a unified embodied foundation architecture that integrates pretrained foundation models as memory-artifact components and continuously turns embodied experience into reusable skills, adaptive memory, and reduced deviation-regret?
Several more specific questions follow.
Q1. How should held-out OOD streams be constructed?
Q2. What is the right unit of effective experience?
Q3. How should pretrained foundation models, policies, skills, and memory structures be integrated into a unified embodied architecture?
Q4. How should foundation models be formalized as memory-artifact components?
Q5. How can embodied experience update memory, skills, reward models, world models, and learned representations?
Q6. What should RL optimize inside an experience-scaling embodied agent?
Q7. How can agents discover reusable skills, options, subgoals, and abstractions under artifact support and bounded resources?
Q8. How can experience-scaling laws be validated in simulation and real-world benchmarks?
These questions can redefine embodied AI research.
X. Vision and Close
I can now return to the title.
When I say “general-purpose robots cannot be pretrained,” I mean: general-purpose robotic capability cannot be fully specified offline, once and for all, by static pretraining alone.
Static pretraining gives an embodied agent an initial capability surface. It can provide semantic priors, perceptual priors, action priors, predictive priors, and useful abstractions. But the long-term ceiling must grow through interaction. The robot must learn from failures, corrections, recoveries, new users, new objects, new layouts, new dynamics, and new preferences. It must decide what to remember, what to forget, what to practice, what to ask, and what to delegate to external artifacts.

My own preferred endpoint is also slightly different from the usual image of fully autonomous general-purpose robots.
For many practical deployments, I think the more meaningful target is general-purpose tools for humans: robots that are broadly programmable, preference-aware, corrigible, and able to improve through use.
The future I want to leave open is not a single giant static model that replaces the human and never changes.
It is a bounded embodied agent that starts with strong priors, treats foundation models as artifacts rather than final intelligence, keeps discovering and refining skills through interaction, manages memory under resource constraints, and remains open to human correction.
That, to me, is the path from pretraining to experience-scaling embodied AI.
References and Works Mentioned
This draft is written as a research opinion manuscript, not a complete survey. The following works and systems are mentioned because they shape the argument developed here.
Reed et al., A Generalist Agent / Gato, 2022.
Brohan et al., RT-1: Robotics Transformer for Real-World Control at Scale, 2022.
Driess et al., PaLM-E: An Embodied Multimodal Language Model, 2023.
Brohan et al., RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control, 2023.
Open X-Embodiment / RT-X, 2023.
Kim et al., OpenVLA: An Open-Source Vision-Language-Action Model, 2024.
Black et al., (\pi_0): A Vision-Language-Action Flow Model for General Robot Control, 2024.
Black et al., (\pi_{0.5}), 2025.
Gemini Robotics and Gemini Robotics-ER, 2025-2026.
GR00T N1, 2025.
Lin et al., Data Scaling Laws in Imitation Learning for Robotic Manipulation, 2024.
Wei et al., Emergent Abilities of Large Language Models, 2022.
Javed and Sutton, The Big World Hypothesis and its Ramifications for Artificial Intelligence, 2024.
Liu et al., LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning, 2023. Project / paper pages: https://libero-project.github.io/main.html and https://openreview.net/forum?id=xzEtNSuDJk
Li et al., BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation, 2023/2024. Project page: https://behavior.stanford.edu/index.html
ARC Prize Foundation, ARC-AGI-3, 2026. Project page: https://arcprize.org/arc-agi/3
Li et al., SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning, 2025/2026. OpenReview page: https://openreview.net/forum?id=TQhSodCM4r
Tan et al., RIPT-VLA: Interactive Post-Training for Vision-Language-Action Models, 2025. OpenReview page: https://openreview.net/forum?id=oXYZHg7HiZ
Physical Intelligence, (\pi^_{0.6}): A VLA That Learns From Experience / RECAP*, 2025. Blog / paper pages: https://www.pi.website/blog/pistar06 and https://arxiv.org/abs/2511.14759